Abstract
Voice conversion (VC) aims to transform speech from a source speaker to a target speaker while preserving the original linguistic content. However, existing VC models typically require large annotated datasets containing transcripts and speaker labels, posing significant challenges for low-resource languages. In any-to-any voice conversion (VC) models that do not rely on annotated datasets, disentangling speaker information from the source speech while preserving linguistic content remains a significant challenge, often resulting in outputs that retain attributes of the source speaker. This paper introduces a novel low-resource VC model that combines knowledge transfer with domain-adversarial training to leverage information from high-resource languages for the benefit of low-resource languages. The proposed approach utilizes pre-trained models, with domain-adversarial training enabling the separation of content from speaker identity without the need for annotated datasets. Objective and subjective evaluations on the low-resource Vietnamese language demonstrate that the proposed model outperforms existing methods in terms of naturalness and speaker similarity in low-resource scenarios.
Sample
Vietnamese Seen-to-Seen
| Source | Target | Conversion | |
|---|---|---|---|
| F_72_43388.wav | M_65_44999.wav | FreeVC FreeVC-SR +KT-WO-ASR | +KT +KT-SR +KT-SR-500-25 +KT-SR-200-10 Phoneme Hallucinator |
| M_65_40008.wav | F_VIVOSSPK38_163.wav | FreeVC FreeVC-SR +KT-WO-ASR | +KT +KT-SR +KT-SR-500-25 +KT-SR-200-10 Phoneme Hallucinator |
| M_65_40008.wav | M_63_40559.wav | FreeVC FreeVC-SR +KT-WO-ASR | +KT +KT-SR +KT-SR-500-25 +KT-SR-200-10 Phoneme Hallucinator |
| F_VIVOSSPK38_163.wav | F_VIVOSSPK16_052.wav | FreeVC FreeVC-SR +KT-WO-ASR | +KT +KT-SR +KT-SR-500-25 +KT-SR-200-10 Phoneme Hallucinator |
Vietnamese Seen-to-Unseen
| Source | Target | Conversion | |
|---|---|---|---|
| M_63_40559.wav | F_biethailong_265_femalenorth.wav | FreeVC FreeVC-SR +KT-WO-ASR | +KT +KT-SR +KT-SR-500-25 +KT-SR-200-10 Phoneme Hallucinator |
| F_VIVOSSPK38_163.wav | M_putinsutroiday-13-193_malesouth.wav | FreeVC FreeVC-SR +KT-WO-ASR | +KT +KT-SR +KT-SR-500-25 +KT-SR-200-10 Phoneme Hallucinator |
| F_VIVOSSPK38_163.wav | F_chuyenthoibaocap-22-1005_femalecentral.wav | FreeVC FreeVC-SR +KT-WO-ASR | +KT +KT-SR +KT-SR-500-25 +KT-SR-200-10 Phoneme Hallucinator |
| M_85_53810.wav | M_phutdunglai-13-3617_malesouth.wav | FreeVC FreeVC-SR +KT-WO-ASR | +KT +KT-SR +KT-SR-500-25 +KT-SR-200-10 Phoneme Hallucinator |
Vietnamese Unseen-to-Seen
| Source | Target | Conversion | |
|---|---|---|---|
| M_nhungngaythoau-11-1369_malenorth.wav | M_85_53775.wav | FreeVC FreeVC-SR +KT-WO-ASR | +KT +KT-SR +KT-SR-500-25 +KT-SR-200-10 Phoneme Hallucinator |
| F_bimathanhtrinhcuatinhyeu-22-286_femalecentral.wav | F_VIVOSSPK16_015.wav | FreeVC FreeVC-SR +KT-WO-ASR | +KT +KT-SR +KT-SR-500-25 +KT-SR-200-10 Phoneme Hallucinator |
| M_putinsutroiday-13-193_malesouth.wav | F_VIVOSSPK38_163.wav | FreeVC FreeVC-SR +KT-WO-ASR | +KT +KT-SR +KT-SR-500-25 +KT-SR-200-10 Phoneme Hallucinator |
| F_thannguoivadatviet_089_femalenorth.wav | M_85_53833.wav | FreeVC FreeVC-SR +KT-WO-ASR | +KT +KT-SR +KT-SR-500-25 +KT-SR-200-10 Phoneme Hallucinator |
Vietnamese Unseen-to-Unseen
| Source | Target | Conversion | |
|---|---|---|---|
| M_putinsutroiday-13-193_malesouth.wav | M_phutdunglai-11-1986_malenorth.wav | FreeVC FreeVC-SR +KT-WO-ASR | +KT +KT-SR +KT-SR-500-25 +KT-SR-200-10 Phoneme Hallucinator |
| M_nhungngaythoau-11-1369_malenorth.wav | F_bimathanhtrinhcuatinhyeu-22-286_femalecentral.wav | FreeVC FreeVC-SR +KT-WO-ASR | +KT +KT-SR +KT-SR-500-25 +KT-SR-200-10 Phoneme Hallucinator |
| F_chuyenthoibaocap-22-1005_femalecentral.wav | F_biethailong_265_femalenorth.wav | FreeVC FreeVC-SR +KT-WO-ASR | +KT +KT-SR +KT-SR-500-25 +KT-SR-200-10 Phoneme Hallucinator |
| F_chodenmaugiaothidamuon_793_femalenorth.wav | M_nhungngaythoau-12-1496_malecentral.wav | FreeVC FreeVC-SR +KT-WO-ASR | +KT +KT-SR +KT-SR-500-25 +KT-SR-200-10 Phoneme Hallucinator |
English Seen-to-Seen
| Source | Target | Conversion | |
|---|---|---|---|
| F_p361_004.wav | M_p246_266.wav | FreeVC FreeVC-SR +KT-WO-ASR | +KT +KT-SR +KT-SR-500-25 +KT-SR-200-10 Phoneme Hallucinator |
| M_p360_157.wav | F_p361_004.wav | FreeVC FreeVC-SR +KT-WO-ASR | +KT +KT-SR +KT-SR-500-25 +KT-SR-200-10 Phoneme Hallucinator |
| M_p279_353.wav | M_p246_109.wav | FreeVC FreeVC-SR +KT-WO-ASR | +KT +KT-SR +KT-SR-500-25 +KT-SR-200-10 Phoneme Hallucinator |
| F_p300_041.wav | F_p361_004.wav | FreeVC FreeVC-SR +KT-WO-ASR | +KT +KT-SR +KT-SR-500-25 +KT-SR-200-10 Phoneme Hallucinator |
English Seen-to-Unseen
| Source | Target | Conversion | |
|---|---|---|---|
| M_p246_034.wav | F_56_1733_000012_000002.wav | FreeVC FreeVC-SR +KT-WO-ASR | +KT +KT-SR +KT-SR-500-25 +KT-SR-200-10 Phoneme Hallucinator |
| F_p300_263.wav | M_17_363_000006_000001.wav | FreeVC FreeVC-SR +KT-WO-ASR | +KT +KT-SR +KT-SR-500-25 +KT-SR-200-10 Phoneme Hallucinator |
| F_p300_263.wav | F_56_1730_000009_000003.wav | FreeVC FreeVC-SR +KT-WO-ASR | +KT +KT-SR +KT-SR-500-25 +KT-SR-200-10 Phoneme Hallucinator |
| M_p360_157.wav | M_17_362_000007_000002.wav | FreeVC FreeVC-SR +KT-WO-ASR | +KT +KT-SR +KT-SR-500-25 +KT-SR-200-10 Phoneme Hallucinator |
English Unseen-to-Seen
| Source | Target | Conversion | |
|---|---|---|---|
| M_17_362_000007_000002.wav | M_p279_350.wav | FreeVC FreeVC-SR +KT-WO-ASR | +KT +KT-SR +KT-SR-500-25 +KT-SR-200-10 Phoneme Hallucinator |
| F_56_1730_000009_000003.wav | F_p323_387.wav | FreeVC FreeVC-SR +KT-WO-ASR | +KT +KT-SR +KT-SR-500-25 +KT-SR-200-10 Phoneme Hallucinator |
| M_17_362_000007_000002.wav | F_p300_041.wav | FreeVC FreeVC-SR +KT-WO-ASR | +KT +KT-SR +KT-SR-500-25 +KT-SR-200-10 Phoneme Hallucinator |
| F_56_1730_000009_000003.wav | M_p246_052.wav | FreeVC FreeVC-SR +KT-WO-ASR | +KT +KT-SR +KT-SR-500-25 +KT-SR-200-10 Phoneme Hallucinator |
English Unseen-to-Unseen
| Source | Target | Conversion | |
|---|---|---|---|
| M_17_362_000007_000002.wav | M_27_123349_000013_000003.wav | FreeVC FreeVC-SR +KT-WO-ASR | +KT +KT-SR +KT-SR-500-25 +KT-SR-200-10 Phoneme Hallucinator |
| M_17_362_000012_000000.wav | F_22_121148_000007_000003.wav | FreeVC FreeVC-SR +KT-WO-ASR | +KT +KT-SR +KT-SR-500-25 +KT-SR-200-10 Phoneme Hallucinator |
| F_30_4445_000044_000001.wav | F_56_1731_000010_000000.wav | FreeVC FreeVC-SR +KT-WO-ASR | +KT +KT-SR +KT-SR-500-25 +KT-SR-200-10 Phoneme Hallucinator |
| F_30_4445_000044_000001.wav | M_17_363_000006_000001.wav | FreeVC FreeVC-SR +KT-WO-ASR | +KT +KT-SR +KT-SR-500-25 +KT-SR-200-10 Phoneme Hallucinator |
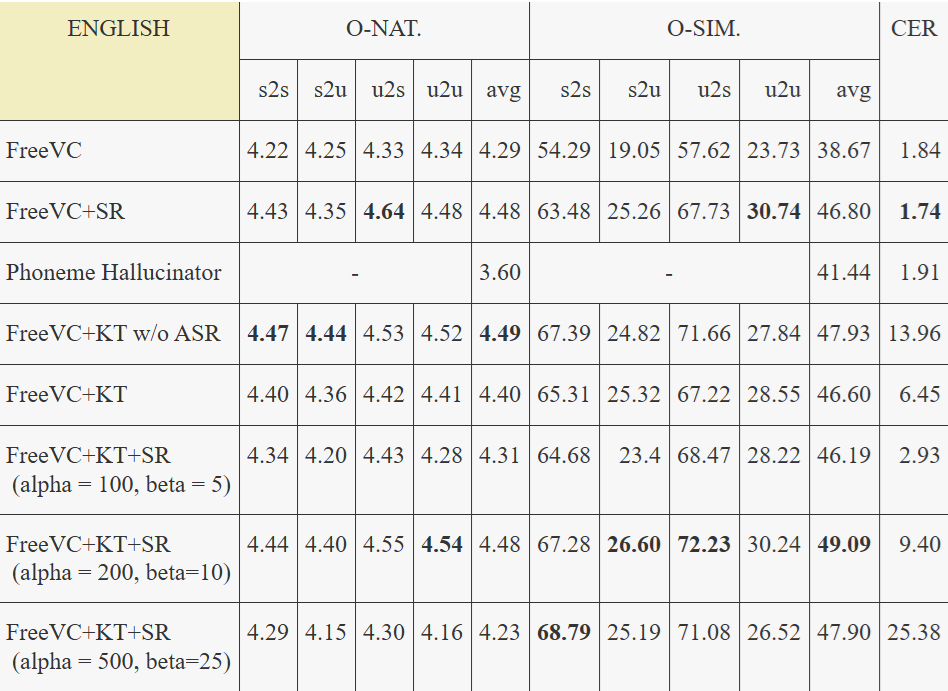
English Results
For the objective evaluation of English results, we employed VCTK as the training dataset and selected speakers from LibriTTS as unseen targets. Regarding data use in test set, refer to section IIIB. CER are obtained using Facebook's Hubert-large-ls960-ft model, while O-SIM was calculated using Titanet-large. Finally, NISQA was employed to compute O-NAT.